35 KiB
----- common params -----
-h, --help, --usage print usage and exit
--version show version and build info
--completion-bash print source-able bash completion script for llama.cpp
--verbose-prompt print a verbose prompt before generation (default: false)
-t, --threads N number of CPU threads to use during generation (default: -1)
(env: LLAMA_ARG_THREADS)
-tb, --threads-batch N number of threads to use during batch and prompt processing (default:
same as --threads)
-C, --cpu-mask M CPU affinity mask: arbitrarily long hex. Complements cpu-range
(default: "")
-Cr, --cpu-range lo-hi range of CPUs for affinity. Complements --cpu-mask
--cpu-strict <0|1> use strict CPU placement (default: 0)
--prio N set process/thread priority : low(-1), normal(0), medium(1), high(2),
realtime(3) (default: 0)
--poll <0...100> use polling level to wait for work (0 - no polling, default: 50)
-Cb, --cpu-mask-batch M CPU affinity mask: arbitrarily long hex. Complements cpu-range-batch
(default: same as --cpu-mask)
-Crb, --cpu-range-batch lo-hi ranges of CPUs for affinity. Complements --cpu-mask-batch
--cpu-strict-batch <0|1> use strict CPU placement (default: same as --cpu-strict)
--prio-batch N set process/thread priority : 0-normal, 1-medium, 2-high, 3-realtime
(default: 0)
--poll-batch <0|1> use polling to wait for work (default: same as --poll)
-c, --ctx-size N size of the prompt context (default: 4096, 0 = loaded from model)
(env: LLAMA_ARG_CTX_SIZE)
-n, --predict, --n-predict N number of tokens to predict (default: -1, -1 = infinity)
(env: LLAMA_ARG_N_PREDICT)
-b, --batch-size N logical maximum batch size (default: 2048)
(env: LLAMA_ARG_BATCH)
-ub, --ubatch-size N physical maximum batch size (default: 512)
(env: LLAMA_ARG_UBATCH)
--keep N number of tokens to keep from the initial prompt (default: 0, -1 =
all)
--swa-full use full-size SWA cache (default: false)
(more
info)
(env: LLAMA_ARG_SWA_FULL)
--kv-unified, -kvu use single unified KV buffer for the KV cache of all sequences
(default: false)
(more info)
(env: LLAMA_ARG_KV_SPLIT)
-fa, --flash-attn [on|off|auto] set Flash Attention use ('on', 'off', or 'auto', default: 'auto')
(env: LLAMA_ARG_FLASH_ATTN)
--no-perf disable internal libllama performance timings (default: false)
(env: LLAMA_ARG_NO_PERF)
-e, --escape process escapes sequences (\n, \r, \t, ', ", \) (default: true)
--no-escape do not process escape sequences
--rope-scaling {none,linear,yarn} RoPE frequency scaling method, defaults to linear unless specified by
the model
(env: LLAMA_ARG_ROPE_SCALING_TYPE)
--rope-scale N RoPE context scaling factor, expands context by a factor of N
(env: LLAMA_ARG_ROPE_SCALE)
--rope-freq-base N RoPE base frequency, used by NTK-aware scaling (default: loaded from
model)
(env: LLAMA_ARG_ROPE_FREQ_BASE)
--rope-freq-scale N RoPE frequency scaling factor, expands context by a factor of 1/N
(env: LLAMA_ARG_ROPE_FREQ_SCALE)
--yarn-orig-ctx N YaRN: original context size of model (default: 0 = model training
context size)
(env: LLAMA_ARG_YARN_ORIG_CTX)
--yarn-ext-factor N YaRN: extrapolation mix factor (default: -1.0, 0.0 = full
interpolation)
(env: LLAMA_ARG_YARN_EXT_FACTOR)
--yarn-attn-factor N YaRN: scale sqrt(t) or attention magnitude (default: -1.0)
(env: LLAMA_ARG_YARN_ATTN_FACTOR)
--yarn-beta-slow N YaRN: high correction dim or alpha (default: -1.0)
(env: LLAMA_ARG_YARN_BETA_SLOW)
--yarn-beta-fast N YaRN: low correction dim or beta (default: -1.0)
(env: LLAMA_ARG_YARN_BETA_FAST)
-nkvo, --no-kv-offload disable KV offload
(env: LLAMA_ARG_NO_KV_OFFLOAD)
-nr, --no-repack disable weight repacking
(env: LLAMA_ARG_NO_REPACK)
--no-host bypass host buffer allowing extra buffers to be used
(env: LLAMA_ARG_NO_HOST)
-ctk, --cache-type-k TYPE KV cache data type for K
allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1
(default: f16)
(env: LLAMA_ARG_CACHE_TYPE_K)
-ctv, --cache-type-v TYPE KV cache data type for V
allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1
(default: f16)
(env: LLAMA_ARG_CACHE_TYPE_V)
-dt, --defrag-thold N KV cache defragmentation threshold (DEPRECATED)
(env: LLAMA_ARG_DEFRAG_THOLD)
-np, --parallel N number of parallel sequences to decode (default: 1)
(env: LLAMA_ARG_N_PARALLEL)
--mlock force system to keep model in RAM rather than swapping or compressing
(env: LLAMA_ARG_MLOCK)
--no-mmap do not memory-map model (slower load but may reduce pageouts if not
using mlock)
(env: LLAMA_ARG_NO_MMAP)
--numa TYPE attempt optimizations that help on some NUMA systems
- distribute: spread execution evenly over all nodes
- isolate: only spawn threads on CPUs on the node that execution
started on
- numactl: use the CPU map provided by numactl
if run without this previously, it is recommended to drop the system
page cache before using this
see https://github.com/ggml-org/llama.cpp/issues/1437
(env: LLAMA_ARG_NUMA)
-dev, --device <dev1,dev2,..> comma-separated list of devices to use for offloading (none = don't
offload)
use --list-devices to see a list of available devices
(env: LLAMA_ARG_DEVICE)
--list-devices print list of available devices and exit
--override-tensor, -ot =,...
override tensor buffer type
--cpu-moe, -cmoe keep all Mixture of Experts (MoE) weights in the CPU
(env: LLAMA_ARG_CPU_MOE)
--n-cpu-moe, -ncmoe N keep the Mixture of Experts (MoE) weights of the first N layers in the
CPU
(env: LLAMA_ARG_N_CPU_MOE)
-ngl, --gpu-layers, --n-gpu-layers N max. number of layers to store in VRAM (default: -1)
(env: LLAMA_ARG_N_GPU_LAYERS)
-sm, --split-mode {none,layer,row} how to split the model across multiple GPUs, one of:
- none: use one GPU only
- layer (default): split layers and KV across GPUs
- row: split rows across GPUs
(env: LLAMA_ARG_SPLIT_MODE)
-ts, --tensor-split N0,N1,N2,... fraction of the model to offload to each GPU, comma-separated list of
proportions, e.g. 3,1
(env: LLAMA_ARG_TENSOR_SPLIT)
-mg, --main-gpu INDEX the GPU to use for the model (with split-mode = none), or for
intermediate results and KV (with split-mode = row) (default: 0)
(env: LLAMA_ARG_MAIN_GPU)
--check-tensors check model tensor data for invalid values (default: false)
--override-kv KEY=TYPE:VALUE advanced option to override model metadata by key. may be specified
multiple times.
types: int, float, bool, str. example: --override-kv
tokenizer.ggml.add_bos_token=bool:false
--no-op-offload disable offloading host tensor operations to device (default: false)
--lora FNAME path to LoRA adapter (can be repeated to use multiple adapters)
--lora-scaled FNAME SCALE path to LoRA adapter with user defined scaling (can be repeated to use
multiple adapters)
--control-vector FNAME add a control vector
note: this argument can be repeated to add multiple control vectors
--control-vector-scaled FNAME SCALE add a control vector with user defined scaling SCALE
note: this argument can be repeated to add multiple scaled control
vectors
--control-vector-layer-range START END
layer range to apply the control vector(s) to, start and end inclusive
-m, --model FNAME model path (default: models/$filename with filename from --hf-file
or --model-url if set, otherwise models/7B/ggml-model-f16.gguf)
(env: LLAMA_ARG_MODEL)
-mu, --model-url MODEL_URL model download url (default: unused)
(env: LLAMA_ARG_MODEL_URL)
-dr, --docker-repo [/][:quant]
Docker Hub model repository. repo is optional, default to ai/. quant
is optional, default to :latest.
example: gemma3
(default: unused)
(env: LLAMA_ARG_DOCKER_REPO)
-hf, -hfr, --hf-repo /[:quant]
Hugging Face model repository; quant is optional, case-insensitive,
default to Q4_K_M, or falls back to the first file in the repo if
Q4_K_M doesn't exist.
mmproj is also downloaded automatically if available. to disable, add
--no-mmproj
example: unsloth/phi-4-GGUF:q4_k_m
(default: unused)
(env: LLAMA_ARG_HF_REPO)
-hfd, -hfrd, --hf-repo-draft /[:quant]
Same as --hf-repo, but for the draft model (default: unused)
(env: LLAMA_ARG_HFD_REPO)
-hff, --hf-file FILE Hugging Face model file. If specified, it will override the quant in
--hf-repo (default: unused)
(env: LLAMA_ARG_HF_FILE)
-hfv, -hfrv, --hf-repo-v /[:quant]
Hugging Face model repository for the vocoder model (default: unused)
(env: LLAMA_ARG_HF_REPO_V)
-hffv, --hf-file-v FILE Hugging Face model file for the vocoder model (default: unused)
(env: LLAMA_ARG_HF_FILE_V)
-hft, --hf-token TOKEN Hugging Face access token (default: value from HF_TOKEN environment
variable)
(env: HF_TOKEN)
--log-disable Log disable
--log-file FNAME Log to file
--log-colors [on|off|auto] Set colored logging ('on', 'off', or 'auto', default: 'auto')
'auto' enables colors when output is to a terminal
(env: LLAMA_LOG_COLORS)
-v, --verbose, --log-verbose Set verbosity level to infinity (i.e. log all messages, useful for
debugging)
--offline Offline mode: forces use of cache, prevents network access
(env: LLAMA_OFFLINE)
-lv, --verbosity, --log-verbosity N Set the verbosity threshold. Messages with a higher verbosity will be
ignored.
(env: LLAMA_LOG_VERBOSITY)
--log-prefix Enable prefix in log messages
(env: LLAMA_LOG_PREFIX)
--log-timestamps Enable timestamps in log messages
(env: LLAMA_LOG_TIMESTAMPS)
-ctkd, --cache-type-k-draft TYPE KV cache data type for K for the draft model
allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1
(default: f16)
(env: LLAMA_ARG_CACHE_TYPE_K_DRAFT)
-ctvd, --cache-type-v-draft TYPE KV cache data type for V for the draft model
allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1
(default: f16)
(env: LLAMA_ARG_CACHE_TYPE_V_DRAFT)
----- sampling params -----
--samplers SAMPLERS samplers that will be used for generation in the order, separated by
';'
(default:
penalties;dry;top_n_sigma;top_k;typ_p;top_p;min_p;xtc;temperature)
-s, --seed SEED RNG seed (default: -1, use random seed for -1)
--sampling-seq, --sampler-seq SEQUENCE
simplified sequence for samplers that will be used (default:
edskypmxt)
--ignore-eos ignore end of stream token and continue generating (implies
--logit-bias EOS-inf)
--temp N temperature (default: 0.8)
--top-k N top-k sampling (default: 40, 0 = disabled)
--top-p N top-p sampling (default: 0.9, 1.0 = disabled)
--min-p N min-p sampling (default: 0.1, 0.0 = disabled)
--top-nsigma N top-n-sigma sampling (default: -1.0, -1.0 = disabled)
--xtc-probability N xtc probability (default: 0.0, 0.0 = disabled)
--xtc-threshold N xtc threshold (default: 0.1, 1.0 = disabled)
--typical N locally typical sampling, parameter p (default: 1.0, 1.0 = disabled)
--repeat-last-n N last n tokens to consider for penalize (default: 64, 0 = disabled, -1
= ctx_size)
--repeat-penalty N penalize repeat sequence of tokens (default: 1.0, 1.0 = disabled)
--presence-penalty N repeat alpha presence penalty (default: 0.0, 0.0 = disabled)
--frequency-penalty N repeat alpha frequency penalty (default: 0.0, 0.0 = disabled)
--dry-multiplier N set DRY sampling multiplier (default: 0.0, 0.0 = disabled)
--dry-base N set DRY sampling base value (default: 1.75)
--dry-allowed-length N set allowed length for DRY sampling (default: 2)
--dry-penalty-last-n N set DRY penalty for the last n tokens (default: -1, 0 = disable, -1 =
context size)
--dry-sequence-breaker STRING add sequence breaker for DRY sampling, clearing out default breakers
('\n', ':', '"', '*') in the process; use "none" to not use any
sequence breakers
--dynatemp-range N dynamic temperature range (default: 0.0, 0.0 = disabled)
--dynatemp-exp N dynamic temperature exponent (default: 1.0)
--mirostat N use Mirostat sampling.
Top K, Nucleus and Locally Typical samplers are ignored if used.
(default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0)
--mirostat-lr N Mirostat learning rate, parameter eta (default: 0.1)
--mirostat-ent N Mirostat target entropy, parameter tau (default: 5.0)
-l, --logit-bias TOKEN_ID(+/-)BIAS modifies the likelihood of token appearing in the completion,
i.e. --logit-bias 15043+1 to increase likelihood of token ' Hello',
or --logit-bias 15043-1 to decrease likelihood of token ' Hello'
--grammar GRAMMAR BNF-like grammar to constrain generations (see samples in grammars/
dir) (default: '')
--grammar-file FNAME file to read grammar from
-j, --json-schema SCHEMA JSON schema to constrain generations (https://json-schema.org/), e.g.
{} for any JSON object
For schemas w/ external $refs, use --grammar +
example/json_schema_to_grammar.py instead
-jf, --json-schema-file FILE File containing a JSON schema to constrain generations
(https://json-schema.org/), e.g. {} for any JSON object
For schemas w/ external $refs, use --grammar +
example/json_schema_to_grammar.py instead
----- example-specific params -----
--ctx-checkpoints, --swa-checkpoints N
max number of context checkpoints to create per slot (default: 8)
(more info)
(env: LLAMA_ARG_CTX_CHECKPOINTS)
--cache-ram, -cram N set the maximum cache size in MiB (default: 8192, -1 - no limit, 0 -
disable)
(more info)
(env: LLAMA_ARG_CACHE_RAM)
--no-context-shift disables context shift on infinite text generation (default: enabled)
(env: LLAMA_ARG_NO_CONTEXT_SHIFT)
--context-shift enables context shift on infinite text generation (default: disabled)
(env: LLAMA_ARG_CONTEXT_SHIFT)
-r, --reverse-prompt PROMPT halt generation at PROMPT, return control in interactive mode
-sp, --special special tokens output enabled (default: false)
--no-warmup skip warming up the model with an empty run
--spm-infill use Suffix/Prefix/Middle pattern for infill (instead of
Prefix/Suffix/Middle) as some models prefer this. (default: disabled)
--pooling {none,mean,cls,last,rank} pooling type for embeddings, use model default if unspecified
(env: LLAMA_ARG_POOLING)
-cb, --cont-batching enable continuous batching (a.k.a dynamic batching) (default: enabled)
(env: LLAMA_ARG_CONT_BATCHING)
-nocb, --no-cont-batching disable continuous batching
(env: LLAMA_ARG_NO_CONT_BATCHING)
--mmproj FILE path to a multimodal projector file. see tools/mtmd/README.md
note: if -hf is used, this argument can be omitted
(env: LLAMA_ARG_MMPROJ)
--mmproj-url URL URL to a multimodal projector file. see tools/mtmd/README.md
(env: LLAMA_ARG_MMPROJ_URL)
--no-mmproj explicitly disable multimodal projector, useful when using -hf
(env: LLAMA_ARG_NO_MMPROJ)
--no-mmproj-offload do not offload multimodal projector to GPU
(env: LLAMA_ARG_NO_MMPROJ_OFFLOAD)
--override-tensor-draft, -otd =,...
override tensor buffer type for draft model
--cpu-moe-draft, -cmoed keep all Mixture of Experts (MoE) weights in the CPU for the draft
model
(env: LLAMA_ARG_CPU_MOE_DRAFT)
--n-cpu-moe-draft, -ncmoed N keep the Mixture of Experts (MoE) weights of the first N layers in the
CPU for the draft model
(env: LLAMA_ARG_N_CPU_MOE_DRAFT)
-a, --alias STRING set alias for model name (to be used by REST API)
(env: LLAMA_ARG_ALIAS)
--host HOST ip address to listen, or bind to an UNIX socket if the address ends
with .sock (default: 127.0.0.1)
(env: LLAMA_ARG_HOST)
--port PORT port to listen (default: 8080)
(env: LLAMA_ARG_PORT)
--path PATH path to serve static files from (default: )
(env: LLAMA_ARG_STATIC_PATH)
--api-prefix PREFIX prefix path the server serves from, without the trailing slash
(default: )
(env: LLAMA_ARG_API_PREFIX)
--no-webui Disable the Web UI (default: enabled)
(env: LLAMA_ARG_NO_WEBUI)
--embedding, --embeddings restrict to only support embedding use case; use only with dedicated
embedding models (default: disabled)
(env: LLAMA_ARG_EMBEDDINGS)
--reranking, --rerank enable reranking endpoint on server (default: disabled)
(env: LLAMA_ARG_RERANKING)
--api-key KEY API key to use for authentication (default: none)
(env: LLAMA_API_KEY)
--api-key-file FNAME path to file containing API keys (default: none)
--ssl-key-file FNAME path to file a PEM-encoded SSL private key
(env: LLAMA_ARG_SSL_KEY_FILE)
--ssl-cert-file FNAME path to file a PEM-encoded SSL certificate
(env: LLAMA_ARG_SSL_CERT_FILE)
--chat-template-kwargs STRING sets additional params for the json template parser
(env: LLAMA_CHAT_TEMPLATE_KWARGS)
-to, --timeout N server read/write timeout in seconds (default: 600)
(env: LLAMA_ARG_TIMEOUT)
--threads-http N number of threads used to process HTTP requests (default: -1)
(env: LLAMA_ARG_THREADS_HTTP)
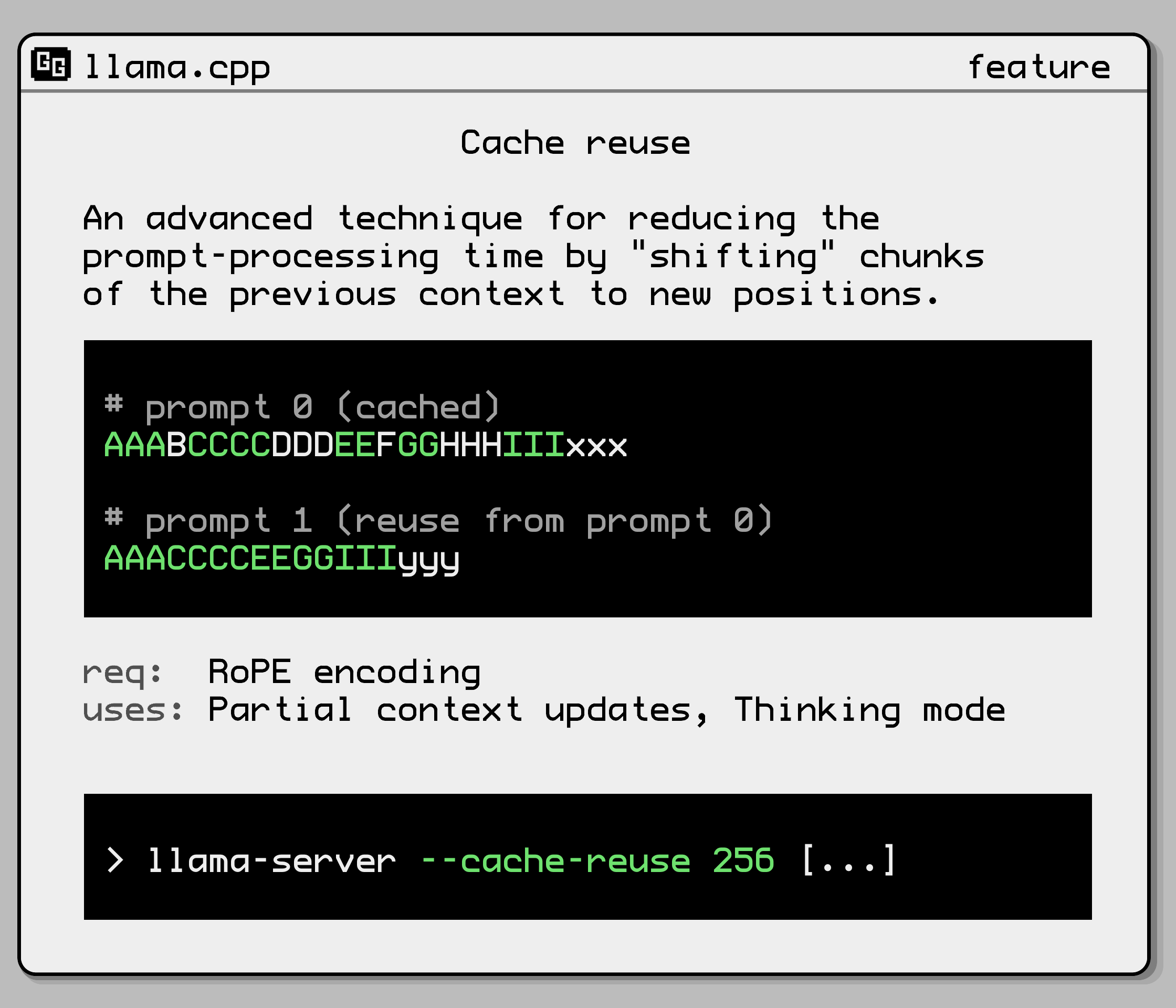
--cache-reuse N min chunk size to attempt reusing from the cache via KV shifting
(default: 0)
(card)
(env: LLAMA_ARG_CACHE_REUSE)
--metrics enable prometheus compatible metrics endpoint (default: disabled)
(env: LLAMA_ARG_ENDPOINT_METRICS)
--props enable changing global properties via POST /props (default: disabled)
(env: LLAMA_ARG_ENDPOINT_PROPS)
--slots enable slots monitoring endpoint (default: enabled)
(env: LLAMA_ARG_ENDPOINT_SLOTS)
--no-slots disables slots monitoring endpoint
(env: LLAMA_ARG_NO_ENDPOINT_SLOTS)
--slot-save-path PATH path to save slot kv cache (default: disabled)
--jinja use jinja template for chat (default: disabled)
(env: LLAMA_ARG_JINJA)
--reasoning-format FORMAT controls whether thought tags are allowed and/or extracted from the
response, and in which format they're returned; one of:
- none: leaves thoughts unparsed in message.content
- deepseek: puts thoughts in message.reasoning_content
- deepseek-legacy: keeps <think> tags in message.content while
also populating message.reasoning_content
(default: auto)
(env: LLAMA_ARG_THINK)
--reasoning-budget N controls the amount of thinking allowed; currently only one of: -1 for
unrestricted thinking budget, or 0 to disable thinking (default: -1)
(env: LLAMA_ARG_THINK_BUDGET)
--chat-template JINJA_TEMPLATE set custom jinja chat template (default: template taken from model's
metadata)
if suffix/prefix are specified, template will be disabled
only commonly used templates are accepted (unless --jinja is set
before this flag):
list of built-in templates:
bailing, bailing-think, bailing2, chatglm3, chatglm4, chatml,
command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3,
gemma, gigachat, glmedge, gpt-oss, granite, grok-2, hunyuan-dense,
hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos,
llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1,
mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch,
openchat, orion, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna,
vicuna-orca, yandex, zephyr
(env: LLAMA_ARG_CHAT_TEMPLATE)
--chat-template-file JINJA_TEMPLATE_FILE
set custom jinja chat template file (default: template taken from
model's metadata)
if suffix/prefix are specified, template will be disabled
only commonly used templates are accepted (unless --jinja is set
before this flag):
list of built-in templates:
bailing, bailing-think, bailing2, chatglm3, chatglm4, chatml,
command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3,
gemma, gigachat, glmedge, gpt-oss, granite, grok-2, hunyuan-dense,
hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos,
llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1,
mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch,
openchat, orion, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna,
vicuna-orca, yandex, zephyr
(env: LLAMA_ARG_CHAT_TEMPLATE_FILE)
--no-prefill-assistant whether to prefill the assistant's response if the last message is an
assistant message (default: prefill enabled)
when this flag is set, if the last message is an assistant message
then it will be treated as a full message and not prefilled
{kind=link}
(env: LLAMA_ARG_NO_PREFILL_ASSISTANT)
-sps, --slot-prompt-similarity SIMILARITY how much the prompt of a request must match the prompt of a slot in order to use that slot (default: 0.10, 0.0 = disabled) --lora-init-without-apply load LoRA adapters without applying them (apply later via POST /lora-adapters) (default: disabled) -td, --threads-draft N number of threads to use during generation (default: same as --threads) -tbd, --threads-batch-draft N number of threads to use during batch and prompt processing (default: same as --threads-draft) --draft-max, --draft, --draft-n N number of tokens to draft for speculative decoding (default: 16) (env: LLAMA_ARG_DRAFT_MAX) --draft-min, --draft-n-min N minimum number of draft tokens to use for speculative decoding (default: 0) (env: LLAMA_ARG_DRAFT_MIN) --draft-p-min P minimum speculative decoding probability (greedy) (default: 0.8) (env: LLAMA_ARG_DRAFT_P_MIN) -cd, --ctx-size-draft N size of the prompt context for the draft model (default: 0, 0 = loaded from model) (env: LLAMA_ARG_CTX_SIZE_DRAFT) -devd, --device-draft <dev1,dev2,..> comma-separated list of devices to use for offloading the draft model (none = don't offload) use --list-devices to see a list of available devices -ngld, --gpu-layers-draft, --n-gpu-layers-draft N number of layers to store in VRAM for the draft model (env: LLAMA_ARG_N_GPU_LAYERS_DRAFT) -md, --model-draft FNAME draft model for speculative decoding (default: unused) (env: LLAMA_ARG_MODEL_DRAFT) --spec-replace TARGET DRAFT translate the string in TARGET into DRAFT if the draft model and main model are not compatible -mv, --model-vocoder FNAME vocoder model for audio generation (default: unused) --tts-use-guide-tokens Use guide tokens to improve TTS word recall --embd-gemma-default use default EmbeddingGemma model (note: can download weights from the internet) --fim-qwen-1.5b-default use default Qwen 2.5 Coder 1.5B (note: can download weights from the internet) --fim-qwen-3b-default use default Qwen 2.5 Coder 3B (note: can download weights from the internet) --fim-qwen-7b-default use default Qwen 2.5 Coder 7B (note: can download weights from the internet) --fim-qwen-7b-spec use Qwen 2.5 Coder 7B + 0.5B draft for speculative decoding (note: can download weights from the internet) --fim-qwen-14b-spec use Qwen 2.5 Coder 14B + 0.5B draft for speculative decoding (note: can download weights from the internet) --fim-qwen-30b-default use default Qwen 3 Coder 30B A3B Instruct (note: can download weights from the internet) --gpt-oss-20b-default use gpt-oss-20b (note: can download weights from the internet) --gpt-oss-120b-default use gpt-oss-120b (note: can download weights from the internet) --vision-gemma-4b-default use Gemma 3 4B QAT (note: can download weights from the internet) --vision-gemma-12b-default use Gemma 3 12B QAT (note: can download weights from the internet)